
IBM Watson Discovery–Overview and Concepts
Disclaimer: This is a personal article. The opinions expressed here represent my own and not those of my current or any previous employers.
Current as of October 2021.
This is the first in a series of articles and tutorials covering Watson Discovery, or “Discovery.”
This Guide will give the reader a deeper technical and practical understanding of Watson Discovery and introduce several related technologies that work with Discovery.
This chapter introduces Watson Discovery, explains how it works at a high level, defines terms used by Discovery, and discusses two common use cases.
What is Watson Discovery?
Watson Discovery is an intelligent search and text analytics platform from IBM. It enables enterprises to quickly and accurately find and unlock insights hidden in documents and other structured and semi-structured information.
Platform
Watson Discovery is part of IBM’s Cloud Portfolio. It is available as a service on the IBM Public Cloud, and Discovery can also run on IBM Cloud Pak for Data within the enterprise and other vendor clouds.
The Platform makes it easy to build, deploy, and run solutions based on an organization’s business needs. It includes the tools needed to configure and run Discovery and ingest and enrich your data and APIs and SDKs to build and deploy custom solutions.
Watson Discovery is integrated with other AI solutions like Watson Assistant, and both take advantage of the cloud fabric and work together seamlessly.
Since Discovery is a cloud-based service, solutions based on Watson Discovery can be configured, tested, and deployed into production quickly, in weeks rather than months or years.
Let’s dig a little deeper into Discovery’s two main roles of Intelligent Search and Text Analytics:
Intelligent Search
Enterprises have always needed to be able to find information quickly and accurately. However, as the volume of information has exploded in recent years, the domains of Information Retrieval and Enterprise Search have struggled to meet this challenge, especially for unstructured information.
The promise of Enterprise Search has been the ability to quickly find the right information no matter the repository or location.
Discovery takes traditional Enterprise Search and Information Retrieval to the next level, leveraging IBM’s rich tradition and experience in these areas and incorporating Artificial Intelligence (AI)and Natural Language Processing (NLP) to understand information and find answers.
So, instead of returning a list of documents, Discovery can find the correct answer to a question or query and return the answer itself.
Text Analytics
With Text Analytics, unstructured information can be augmented or processed to extract meaning, identify relationships, or even turned into structured data to be used with Data Analysis tools.
In Watson Discovery, NLP is combined with AI techniques like classification and topic modeling to identify and extract facts in text.
Discovery has a compelling and unique interactive Content Miner that uses Text Analytics to interactively find insights from vast amounts of data and information for producing reports and making decisions.
How Does Watson Discovery Work?
The simple answer is that Discovery ingests documents, processes them, and creates a searchable index. Users can then query the index, i.e., ask questions, to quickly find information and answers contained in the original documents.
A good thing to keep in mind is that Discovery, at its core, works on text. This means that non-textual data is first converted to text so that Discovery can understand it.
To see how Discovery works, let’s take a closer look at the two main activities: Collection Building and Search.
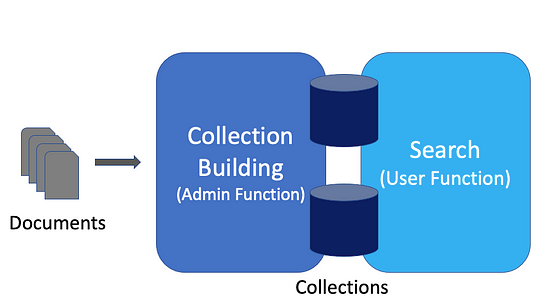
Collection Building
A collection is a set of documents that you want to search, along with all of the metadata and the data extracted or created by Discovery that goes with the set of documents.
A document is a chunk of information. It may not be a traditional document, as in a book, but it might be. It could be a chapter, page, paragraph, or a few sentences or phrases. It could be a PDF, Word, PowerPoint, spreadsheet, or a row in a spreadsheet. It could be a row in a database or a JSON data structure.
A document is composed of fields, which contain the text or body of the document and other related information. Some examples of fields are Title, Text, Section, etc. How fields are defined and arranged in Discovery will be covered in-depth in a future chapter of this handbook.
Collection Building is the process of taking in or ingesting a set of documents and then turning them into a searchable collection.
Once a collection has been created, it is useful to ingest a small representative set of documents and then iterate on Collection Building until the desired state of a collection is achieved, ingesting the full set of documents to finalize the collection.
Ingestion, conversion, enrichment, and indexing form an iterative pipeline and are explained in more detail below.
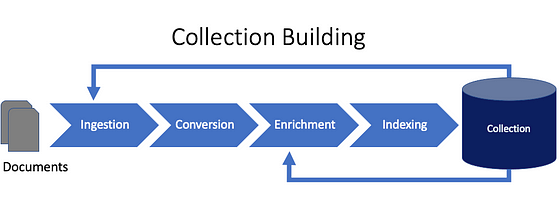
Ingestion
Ingestion is the process of taking documents into the Discovery system. Ingestion can use Connectors to connect to repositories like Sharepoint or SalesForce, or a Crawler to download documents and pages from websites or filesystems. A user or administrator can upload documents using Discovery’s tooling (the User Interface or UI) or programmatically using the Discovery API.
Conversion
Ingested documents are converted from their original formats (PDF, Word, etc.) into an internal data structure used by Discovery. In most cases, the text of a document is retained, while visual and structural elements are discarded. However, there are some exceptions to this, as we shall see later in the series.
You may use an AI tool called Smart Document Understanding (SDU) during the conversion process to identify various parts or elements of documents where there is a common or similar format. SDU uses Machine Learning, and it can be trained to recognize document elements based on visual patterns and structures.
Several pre-trained Machine Learning (ML) models are available out of the box. The Discovery tooling also allows users to train new ML models (Custom Models) to apply to a collection.
Documents processed using SDU are converted to both HTML and text to leverage structural information in the search and rendering process, with additional enrichments.
The conversion process also allows documents to be split into smaller documents by specifying a field for splitting (for example, section heading). This is usually a field identified and populated by the SDU model.
Enrichment
An Enrichment adds some additional information or intelligence to a document. You can do this by identifying, extracting, and tagging (or annotating) information from the document itself, adding external information based on document content or synthesizing additional information based on document content. In some cases, enrichments will identify and label relationships between objects in a document.
Enrichments create additional fields which are attached to the document and stored in the index. Enrichments are applied whenever a document is reprocessed.
Watson Discovery provides many out-of-the-box enrichments and the opportunity to add customized enrichments using tools like Watson Knowledge Studio.
Indexing
The index is Discovery’s internal representation of a collection. It can contain many related files, built into efficient, fast search and retrieval structures, and persists on some storage devices. However, this is all abstracted from Discovery users and acts as a “black box.”
The index is updated any time a document is added, updated, or deleted. Once the index is built, a collection is ready to be searched, and users can perform a search at the same time new information is being added or updated.
Search
Search is the process of finding information stored in a collection based on criteria entered by the user. The search results can be returned to the user in many different ways, depending on the application.
Search is often an iterative process, allowing the user to cast a “wide net” to bring back general results and then to iterate by refining the results until the desired outcome is achieved.
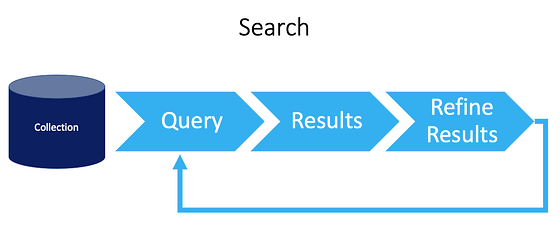
Query
A query is the criteria defining what to search for and what to return in the results.
With Discovery, the simplest type of query is called a Natural Language Query. A phrase or question, expressed in the user’s “natural” language, can be used to search a collection or several collections and return results.
Discovery tooling and the Discovery API provide for more complex queries using the Discovery Query Language.
Discovery provides an end-to-end capability for Search in the tooling to allow for Collection Building and Refinement. However, the tooling is not intended to be used as an end-user application at scale.
Reusable User Interface (UI) components and a sample search application are available for developers to use to customize and build search-based applications intended to be used for production systems.
Results
Search results are traditionally displayed as a list of documents, with a title linked to the original document and a “snippet” of text for each document, in context, to allow quick evaluation of the results to see if they satisfy the intent of the search.
Discovery makes it easy to implement traditional as well as AI-infused searches.
For example, instead of a fixed snippet of text, Discovery can return a list of actual passages matching the query for each document in the results or the “best” passage(s) from each document.
Discovery can also be configured and trained to return actual answers found in documents. Note that this is currently a beta feature and is not guaranteed to be in future versions.
Enrichments and metadata can also be configured returned in the results displayed in the User Interface to help evaluate the results.
Fields can be configured and returned with results as facets, allowing quick and easy refinement or “drill down” of the results by selecting facet values.
For Content Mining collections, various visualizations like time series, word clouds, and heat maps work together to help users interact with the results and identify insights.
Improving Results
Additional AI-based techniques can be used to “improve” search results.
Relevancy Training allows the order of documents in the results to be changed so that the most important documents for a specific query always appear at the top.
Curation, currently a beta feature, allows a specific document or answer always to be returned as the first result for a given question.
Other techniques like Classification can help the user make sense of the results and quickly determine which items to select.
We’ll talk about all of these features in future articles in the series.
How Would I use Watson Discovery?
Two representative use cases for Discovery are Enterprise Search and Customer Care.
Enterprise Search
Enterprise Search is the process of finding and connecting to information needed by the enterprise. Enterprise information is found in both structured and unstructured sources. Sometimes structured information is referred to as data, and unstructured information, documents, but in recent years the boundary between the two has become less defined. As a result, structured documents (documents that contain attached or embedded data and information) have become the norm.
Typically, when used for Enterprise Search, Discovery is installed on CloudPak for Data instances running inside enterprise firewalls. This simplifies security and allows for better access to enterprise data sources.
Enterprise sources include intranets, repositories like SharePoint, Content Management systems like FileNet, various types of databases, and file shares. Collections are built for these sources and become searchable from a single query.
The strength of Enterprise Search is in unlocking information stored in various silos in the organization and making them available from a single point of search.
Customer Care
Watson Discovery can play several key roles in Customer Care use cases.
One such Use Case is for Customer Call Centers, where Watson Assistant is trained and configured to answer Frequently Asked Questions (FAQs) and perform other tasks. Here, the Search Skill in Watson Assistant can send questions to Watson Discovery when Assistant cannot answer a question or provide an answer.
In this case, Watson Discovery can be trained and configured to provide an accurate response to a user inquiry using the documents in its collection, which are kept up to date and synchronized with their data sources.
The next Customer Care use case is Agent Assist. Here, human agents on the telephone with customers can use Discovery to quickly find information needed to answer questions or provide customer support. For this scenario, Discovery might also include collections created from Customer Relationship Management (CRM) systems or Support systems.
Finally, the Content Miner application of Watson Discovery can index large volumes of call center conversations, support tickets, surveys, and other customer information, and interactively identify trends, hot topics, emerging problems, root causes of problems, and other insights.
Summary
In this chapter, we have introduced Watson Discovery and some of its capabilities. We have taken a look at how it works at a very high level. And we have seen some practical uses in Enterprise Search and Customer Care. In subsequent chapters, we will take a more in-depth look at Discovery and take a deep dive into each feature.
How Do I Get Started?
To try out Discovery, you can get started today here: https://cloud.ibm.com/docs/discovery?topic=discovery-getting-started