
Watson Discovery: On Plans, Projects, Collections, and Collection Types
Discovery Guide Series
Updated on Dec 16, 2021
In this chapter, we will talk about Collections, how Discovery uses Projects to organize Collections, and cover some of the differences between the available Plans.
Definitions
To set the stage, here are some definitions:
-
Service – Watson Discovery is a service running either on the IBM Cloud (Public Cloud) or on IBM Cloud Pak for Data (CP4D) installed at an organization’s site or on any cloud. A provisioned instance of Discovery is also called a Service Instance.
-
Plan – A plan is required to provision a Service Instance of Discovery on the IBM Cloud. A Plan is an online subscription. The Plan level determines the features you will have available for your Discovery instance. You can get up-to-date information on plans HERE.
-
Project – A project is used to organize collections.
-
Collection – A collection is a set of documents that can be searched, along with metadata and configuration information.
We’ll cover each of these in more detail.
Service and Plans
To do anything with Watson Discovery, you will need to create an instance of Discovery. The Service Instance runs the cloud version Discovery and all the User Interface (Tooling) elements used to configure Discovery. When you create a Service Instance of Discovery, you must select a plan.
As of this writing, there are three plans available: Plus, Enterprise, and Premium.
There is no “free” plan, but the Plus plan offers a 30-day trial period. Once you go over the 30-day period, your account will be charged. Additional instances of Discovery will also be charged to your account (so you can’t delete your instance before you reach the 30-day limit and then create another instance to get more free days).
The Plus and Enterprise plans offer a Multi-Tenant Cloud environment. This means that you will share compute and storage resources with other customers. The Premium plan offers an isolated single-tenant environment where usage and training data are private and additional security features are enabled.
The Plus plan has the most limitations on the number and size of documents you can index and the number of queries per month, but it is fine for experimentation (as long as you don’t go over your free days) or small-scale users. It offers basic collection types and features.
The Enterprise plan offers more volume and higher performance, and additional functionality. Most notably, the Enterprise plan offers Content Mining and Document Retrieval for Contracts collection types which are not available in Plus. We’ll take a look at those collection types later in this manual.
The Premium plan offers the greatest flexibility and all of the features of Discovery, in addition to greater security, single tenancy, High Availability, and Disaster Recovery. It is also the only plan to offer Service Level Uptime guarantees.
Please see the IBM Cloud Documentation for more complete details and the latest information on Discovery Plans.
Projects
Think of a Project as a folder for collections. Each project can hold multiple collections, but all collections in a project must be of the same type. The exception is that a Text Mining project may only contain a single collection. When you create a project, you must choose the Project Type. The project type will determine the collection types for the project.
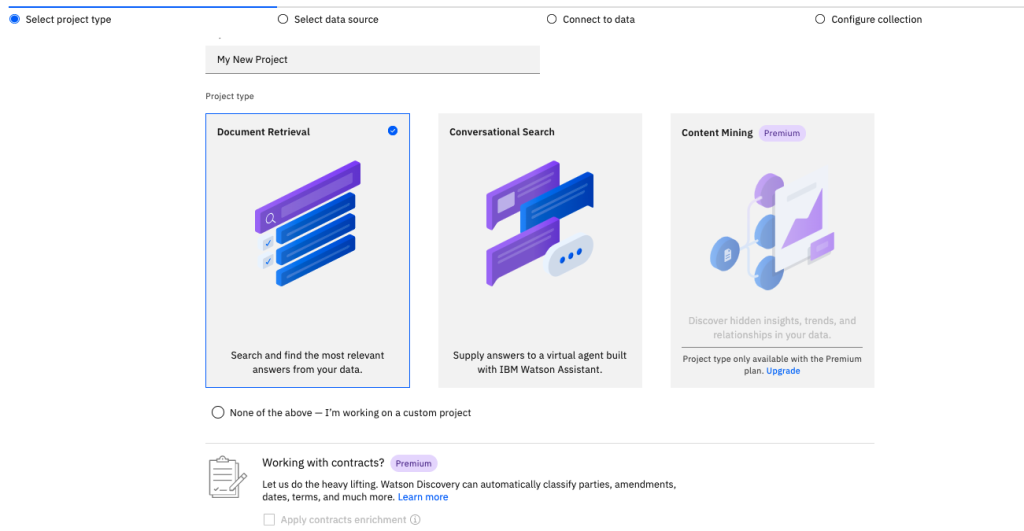
Users may search all collections in a project from a single query, and results will be aggregated.
Collections
The project type determines available Collection Types. The collection type determines the default configuration of a collection and determines the enrichments that can be applied to the collection. When you create a collection, you also choose a data source for that collection. This cannot be changed after the collection is created.
The Plus plan allows for three basic collection types: Document Retrieval, Conversational Search, and Custom. The Premium plan adds additional Collection types, which we will cover later in the Handbook.
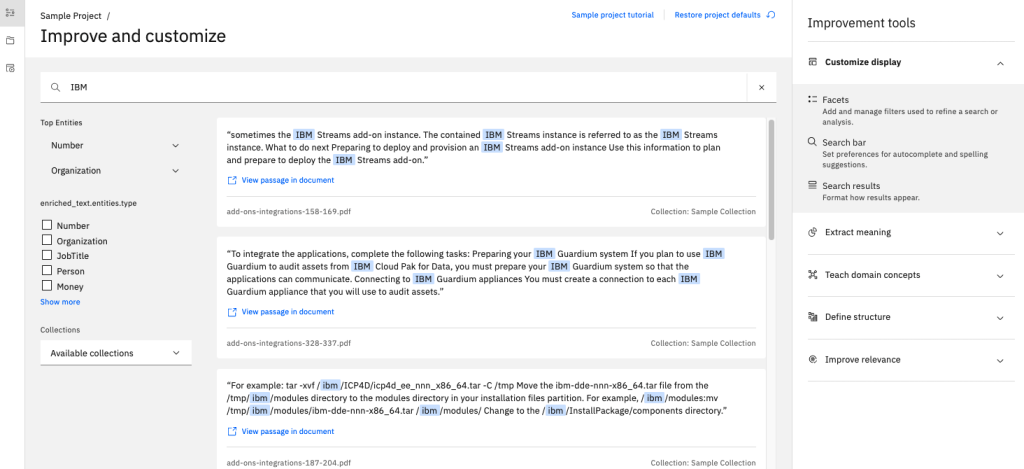
Document Retrieval collections provide a “Search and Retrieve” capability, similar to Google and other search applications. Document Retrieval collections are configured with Entities and Parts of Speech enrichments enabled. These enrichments can help filter or drill down into search results to find documents more quickly. The Tooling (User Interface) for a Document Retrieval collection provides basic query, facet, and results capabilities. Full text and JSON views are available for documents from the results.
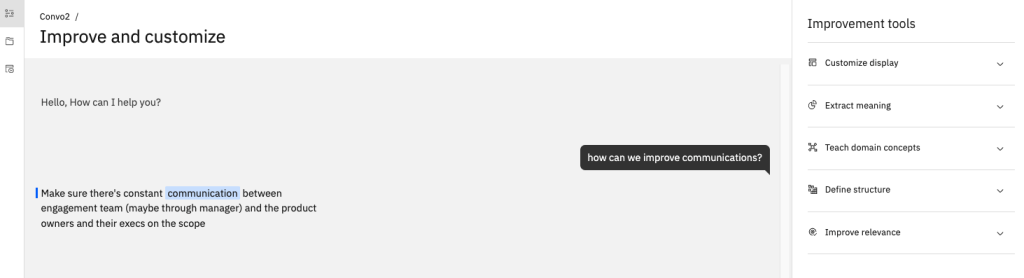
Conversational Search collections are intended to provide fairly short answers to user questions and are typically used for Chatbot and Virtual Agent type applications. Tooling for the Conversational Search collection type mimics a chatbot, and by default, returns a single answer to a query or question. Enrichments are not initially enabled for Conversational Search collections, but they can be added after a collection is created.
Custom collections are essentially Document Retrieval collections without any enrichments applied. However, they can be customized later by enabling enrichments. The tooling for Custom collections is identical to the Tooling for Document Retrieval collections.
Summary
This chapter provided an overview of projects and collections. The next chapter will show how collections are created and populated with documents.